
Background
In this comprehensive article, we will delve into the art of seamlessly integrating LLMs into your organization’s question answering chatbot. Brace yourself for a deep dive into the high-level system design considerations, as well as the nitty-gritty details of the code implementation.
While the potential of intelligent Q&A and LLM integration is significant, organizations often face several challenges:
- Availability and Quality of Training Data: LLMs need vast amounts of high-quality data for training. Organizations may struggle to gather sufficient and relevant data specific to their domain or industry. Ensuring the accuracy and diversity of the training data is essential to avoid biased or skewed responses from the Intelligent Q&A.
- Integration with Existing Knowledge Base: Many organizations have extensive proprietary data and domain-specific information. Effectively integrating this knowledge with LLMs can be complex, requiring careful mapping, preprocessing, and structuring of the data. Privacy and security concerns must also be addressed when incorporating sensitive information into the Intelligent Q&A.
- Contextual Understanding and Response Generation: LLMs, while powerful, can struggle with context disambiguation and nuanced queries. Enhancing the comprehension and response capabilities requires robust natural language processing techniques and fine-tuning strategies.
- Scalability: As organizations grow, the Intelligent Q&A must handle an increasing volume of queries while maintaining optimal performance. This involves addressing response latency, managing concurrent requests, and efficient resource allocation.
Addressing these challenges requires technical expertise, domain knowledge, and iterative development processes from various functional teams.
Welcome to the world of intelligent Q&A empowered by LeetTools
LeetTools provides an advanced solution that leverages a sophisticated knowledge base and cutting-edge technologies to deliver accurate, contextually relevant responses.
Here’s a comprehensive overview of how LeetTools revolutionizes intelligent Q&A:
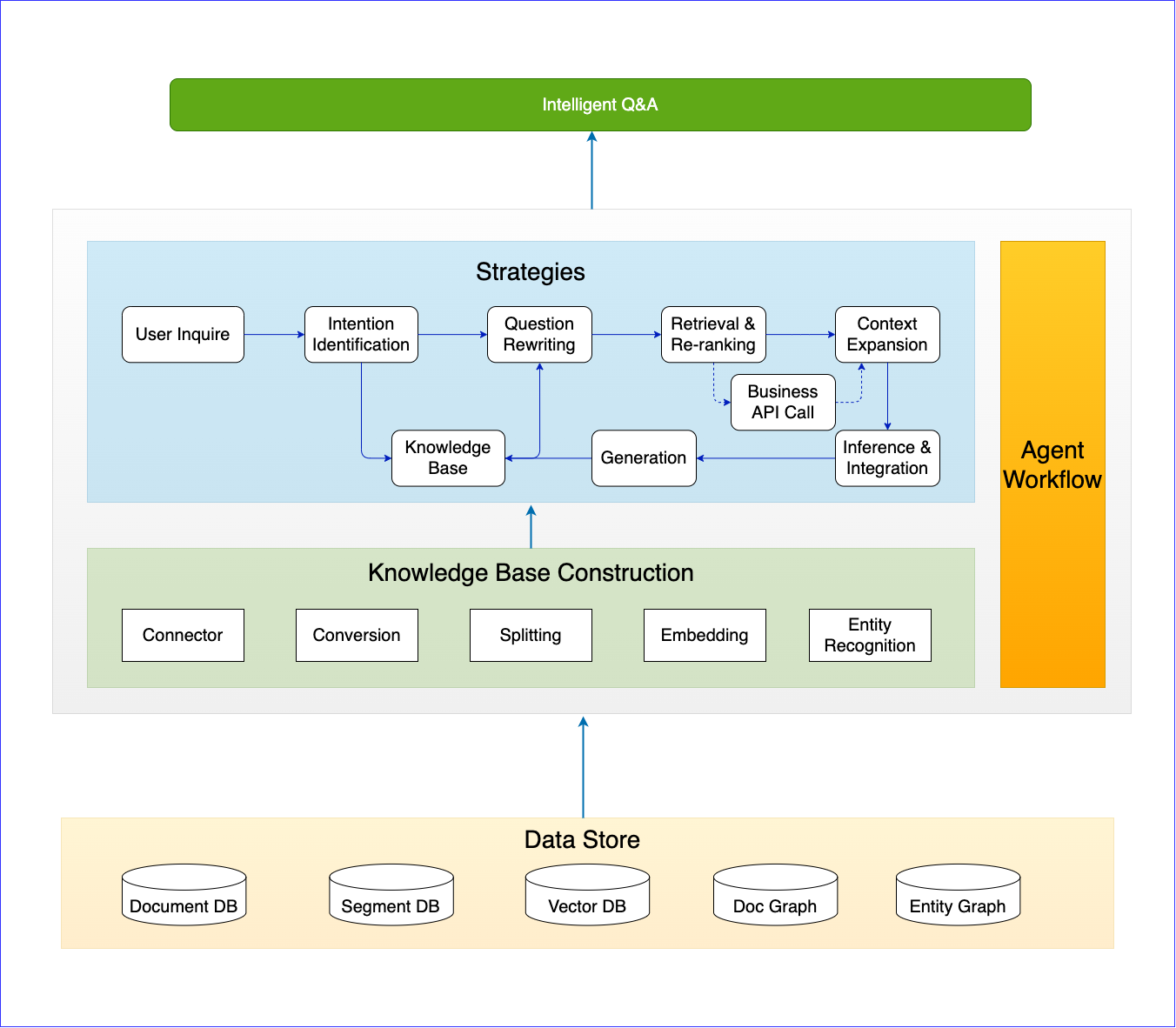
- Data Store:The knowledge base is designed with multiple types of databases: Document DB, Segment DB, Vector DB, and Graph DB. This architecture unifies the processing of documents in different formats, creating a structured and searchable knowledge repository. Traditional Split & Embedding approaches often lose the relational connections between pieces of knowledge. The addition of a graph database addresses this issue with its robust capability to handle these relationships. It forms a solid foundation for knowledge graphs, crucial for resolving interrelated knowledge points. Through the graph database, each knowledge point is enriched with semantic links, creating a dynamic network that preserves and enhances the textural relationships of knowledge, providing deeper insights and understanding during knowledge retrieval and analysis.
- Knowledge Base Construction: The knowledge base is built through the steps of Convert, Split, Embedding, and Entity Recognition, stored in the SegmentDB, DocGraph, Segment Embedding, and EntityGraph.
- Strategy: Leveraging the knowledge base, we implement a new Graph RAG (Retrieval-Augmented Generation) processing flow that uses LLM capabilities. This involves user query Intent Recognition, Question Rewriting, Retrieval, Re-ranking, Context Expansion, and Inference, ultimately generating answers through the Generator.
- Agent Workflow: By assigning tasks to different agents as workflows—such as intent recognition, question rewriting, and keyword searching—the system significantly reduces the time and manpower required for manual operations, enhancing the accuracy and consistency of the output results.
- intelligent Q&A: Users can perform multi-turn intelligent Q&A based on the business knowledge base by inputting Keywords, Questions, or Commands. Each historical search and piece of generated content is meticulously integrated, enriching the knowledge base with a wealth of information.
Knowledge Base Construction Process
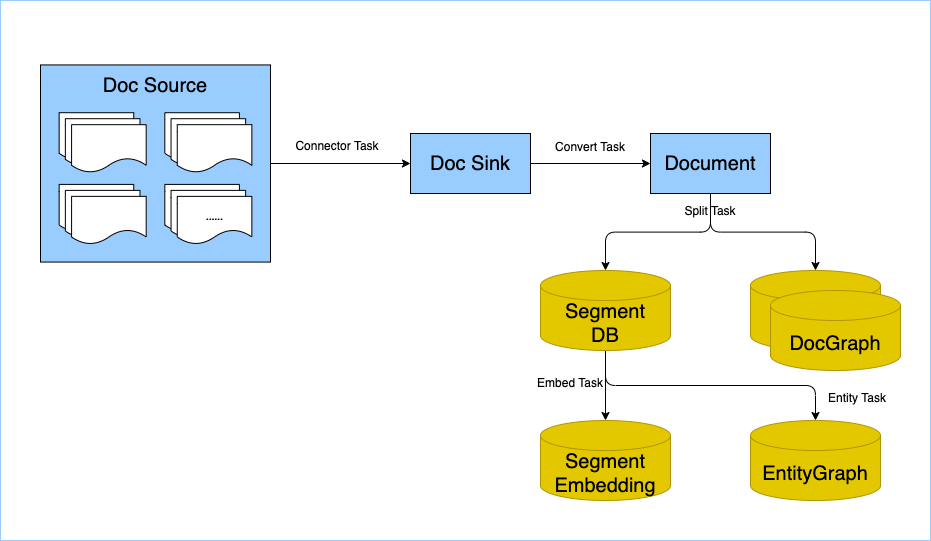
SegmentDB
Stores segmented text fragments along with their metadata in a relational database for efficient querying and management. The metadata, organized in a MySQL database, includes fields such as document ID, text fragment, order within the source document, creation time, and update time. This structured approach ensures quick access and easy management of text fragments, facilitating seamless integration and retrieval of information within the knowledge base.
For example:
1 | CREATE TABLE segments ( |
DocGraph
Stores inter-document relationships to build a comprehensive document graph using a graph database. In this system, nodes represent documents with attributes such as document ID, title, and publication time. Edges denote the relationships between these documents, incorporating attributes like relationship type (e.g., citation, similarity, annotation) and more. This structure allows for efficient querying and analysis, enhancing the interconnectedness and contextual understanding within the knowledge base.
For example:
1 | d1:Document {document_id: 1, title: 'metric_guidelines', time: '2024'} |
Segment Embedding
Stores embedding vectors of text fragments to enhance similarity searches and text retrieval. The segment_embeddings table includes fields such as the associated text fragment from SegmentDB, embedding vectors (arrays), creation time, and additional metadata. This setup enables efficient and accurate searches within the knowledge base, allowing for advanced text analysis and retrieval capabilities.
For example:
1 | { |
EntityGraph
Constructs an entity graph to visualize relationships between entities, enriching contextual information for intelligent Q&A. A graph database stores entity nodes and their relationships, enabling efficient graph queries and relationship analysis. Entity nodes include attributes like entity ID, name, and type, while edges represent the connections between entities, with attributes such as relationship type (e.g., belongs to, influences, associates) and more. This structure provides a detailed and interconnected understanding of entity relationships within the knowledge base.
For example:
1 | CREATE (e1:Entity {entity_id: 1, name: 'Southern Power Grid', type: 'Company'}) |
Customized Strategy
LeetTools employs a self-developed framework for tailored strategy development and automated execution. Utilizing Retrieval-Augmented Generation (RAG) technology, it produces accurate and relevant text outputs. By incorporating processes such as intent recognition, question rewriting, querying, re-ranking, context expansion, and inference, LeetTools accurately understands user queries and delivers comprehensive, precise, and personalized answers.
For example, when a user inputs, “Which indicators are low in xx district?”, LeetTools follows these steps to provide a detailed response.
Intention Recognition
The model identifies the user’s intent as covering three main aspects:
- Determine the signing rate of the safety production responsibility agreement in xx district.
- Identify potential types of accidents that may occur.
- Find measures to prevent such accidents.
Question Rewriting
The user query is broken down into three specific questions:
- “What is the signing rate of the safety production responsibility agreement in xx district?” (region: xx district, metric: signing rate)
- “What types of accidents might be linked to a low signing rate of the safety production responsibility agreement?”
- “What measures can be taken to prevent accidents associated with a low signing rate of the safety production responsibility agreement?”
Search
Using the rewritten questions, conduct searches across various data sources, including the knowledge base, safety procedure documents, and accident case databases.
Potential search results may include:
- The specific signing rate of the safety production responsibility agreement in xx district.
- Types of accidents historically associated with the signing rate of the safety production responsibility agreement.
- Preventive measures outlined in safety procedures to avoid such accidents.
Rerank
Re-rank the search results to prioritize answers that are rich in information and most relevant to the query intent.
- Implement domain-specific rules to prioritize authoritative sources, such as government documents and industry standards.
Context Expansion
- Analyze safety accident situations in other districts of xx city for comparative insights.
- Integrate the industrial characteristics and historical accident data of xx district to conduct a detailed analysis of potential accident types.
Inference
Integrate all gathered information to perform logical reasoning and a comprehensive analysis.
- Evaluate accident risk levels.
- Recommend targeted preventive measures based on accident case studies and safety procedures.
Generation
Generate the final answer, which includes:
- The specific signing rate of the safety production responsibility agreement in xx district.
- An analysis of the types of safety accidents associated with the signing rate of the safety production responsibility agreement.
- Tailored preventive measures and suggestions to address the actual situation in xx district and prevent related accidents.
Intelligent Q&A Processing Flow
LeetTools leverages the natural language processing capabilities of large models and the extensive information in its knowledge base to quickly and accurately answer questions based on business-specific data.
Example User Input: “Which indicators are low in xx district?”
Processing Flow:
- User Query: Users pose questions in natural language, such as “Which indicators are low in xx district?” or “What is the cause of the trip in XX line?” These questions typically involve multiple dimensions, including grid topology, equipment parameters, operating status, historical data, and warning information.
- Question Analysis: The system employs Named Entity Recognition (NER) technology from large models to extract key entities from the user’s question, such as “xx district,” “substation,” and “line.” It then uses relationship extraction technology to identify relationships between entities, such as “low” and “trip.” Dependency syntax analysis and other techniques further clarify the semantics and intent of the question, determining its relevance to risk indicator values.
- Knowledge Base Retrieval and API Calls:
- Risk Indicator Value Related Questions: For questions involving risk indicator values in a specific area (e.g., “xx district”), the system calls business APIs to obtain relevant data, including indicator names, values, rankings, risk levels, and accident chains. If the area is unspecified, the user is prompted to provide it.
- Non-Risk Indicator Value Related Questions: The system searches the knowledge base for relevant information, including electrical equipment parameters, operating procedures, historical accident cases, and risk assessment models. It also supplements the context with grid topology relationships and equipment associations from the graph database.
- Information Integration: The system integrates retrieved knowledge and API data with real-time system data (current, voltage, power, etc.) and historical data (equipment operating records, fault records, weather data, etc.) for multidimensional analysis. This analysis uses both rule-based reasoning (e.g., determining overload conditions based on equipment parameters and operating procedures) and model-based reasoning (e.g., using fault diagnosis models to analyze the cause of trips).
- Answer Generation:
- Risk Indicator Value Related Questions:
- Example: For “Which indicators are low in xx district?”, if the “safety production responsibility agreement signing rate” is low, the system might respond: “The safety production responsibility agreement signing rate in xx district is 35%, which is considered low. Potential risks include personal injury, health impairment, and mechanical equipment damage. The main reasons include…; suggested measures are…”
- For normal indicators, the system generates responses with the indicator name, value, and ranking.
- If the relevant indicator name cannot be analyzed, it returns all indicator information for the area.
- Non-Risk Indicator Value Related Questions: The system uses Natural Language Generation (NLG) technology to produce natural and fluent answers, providing supporting evidence and references, such as related rules, models, and cases, to enhance credibility. For example, for “What is the cause of the trip in the line?”, the system might respond: “The cause of the line trip is… Based on historical case analysis, it is recommended that…”.
- Risk Indicator Value Related Questions:
- User Feedback and Iterative Optimization: LeetTools encourages users to provide feedback on the answers, collecting evaluations on satisfaction, accuracy, and completeness. This feedback is used to assess model performance and is crucial for model training and knowledge base updates. This process supports continuous learning and system optimization, enhancing the system’s intelligence and service quality over time.
1 | original query: Which indicators are low in xx district? |
Through this process, the system intelligently understands user queries, accurately retrieves relevant knowledge, comprehensively analyzes real-time and historical data, and generates persuasive answers. This approach offers efficient and reliable decision support for professionals in the field.
Conclusion
LeetTools represents a significant advancement in the field of intelligent Q&A systems. By integrating large language models (LLMs) with a robust, multi-faceted knowledge base, LeetTools can effectively process complex user queries and provide accurate, contextually relevant answers. The system’s ability to perform detailed analyses using both real-time and historical data, coupled with its advanced natural language processing capabilities, ensures that users receive comprehensive and reliable decision support. Continuous feedback and iterative optimization further enhance the system’s performance, making LeetTools an indispensable tool for professionals seeking efficient and informed decision-making. As we continue to refine and expand its capabilities, LeetTools stands poised to set new standards in intelligent query handling and knowledge management.